"他人"は見た! 雪餅ののめゲーム配信 5
はじめに
このシリーズ、基本的には 直近の配信+過去の気になる配信 で書いていたのですが、某スプラ3の影響で過去回まで入れようとすると時間がかかりそうだったので、今回は直近の配信から( ˘ω˘)
スプラトゥーン3
前作のスプラトゥーン2に続き、2022年9月9日にスプラトゥーン3が発売されました。
今回は発売前に行われた前夜祭、ヒーローモード、フェスに挑戦しています。
前夜祭
9/9の発売に先駆けて8/28に行われた前夜祭。
使えるブキが限られていたり戦績は製品版に引き継がれないなど制約はあるものの、一足早くスプラ3を楽しめるこのチャンスを逃すはずがない!
ということで、まさかの?全ブキで勝てるまで終わりません配信がスタートしたわけですね。
スタートしたと思ったらえらくコアな解説がwww
全部盛りとか全年齢向けゲームでええんかwww(気持ちはわからんでもない)
アルセウスなどもそうでしたが、のめさんが嬉しそうに楽しそうにしている様子が本当に良いですね☺
とはいえいざ試合が始まればそこはもう阿鼻叫喚の世界…。
並のホラゲよりホラゲらしい悲鳴が堪能できますw
チーム戦だけにのめさんが活躍 = 勝利 ではない辺りは難しいところですが、使い慣れないブキに苦戦しつつもスプラ2で鍛えたウデマエやチームの助けもあり、程よいペースで進んでいきます。
私のような3から始めました勢は各ブキの雰囲気がなんとなくつかめる、という意味でも良い配信だと思います。
(ヒーローモードでは色んなブキが使えますが、対人戦とはまた感覚が異なりますし、自分で揃えるのもなかなか大変)
最後は残念でしたが、9/9以降にも期待が持てますね(๑•̀ㅂ•́)و✧
【スプラ3】初ヒーローモード!覚悟はいイカ!?【雪餅ののめ/VTuber】
ということでスプラ3一発目。
私が YouTuber、VTuber を追い始めたのが遅かったためか、スプラ2配信は大体どの方もオンライン対戦ばかりだったので自分で3をプレイして初めて知ったのですが、スプラトゥーンには対戦の他に一人でプレイするヒーローモードがあります。
今回はヒーローモードに挑戦。
スプラ2以前にもあったとはいえ、3になって結構変わったようで、そもそもコジャケが今回初というのは地味にびっくりしました。
こういう前作との違いというのは、3から始めた自分にはない視線なのでなかなか興味深いところです。
また、前作との違いに驚きながら楽しむ様子が良いですね☺
各ステージはサクサククリアしていっていて、流石です👏
むしろ出てくる内容に解説が追いつかない問題がwww
最後はナワバリバトルでシメ…なのですが…。
ある意味予想された未来だったのかもしれないwww
【スプラ3】持っていくならマンタローの笑顔を一つ【雪餅ののめ/VTuber】
9/24〜9/26にかけて行われたフェスに参加したときの配信です。
まずはフェス中ならではのおすすめスポットの紹介から。
って、やっぱりここなのねww
確かにこれからの季節にぴったりですよね。
フェスでは通常時のレギュラーマッチと同様のナワバリバトルと、3チームで戦うトリカラバトルがあります。
中間発表時1位の暇つぶし派であったため、ナワバリバトルをプレイしつつトリカラバトルを待つ、という形で進めていきます。
いざ試合が始まってみると、そこに広がる悲鳴と暴言の嵐www(一部誇張表現があります)
まぁいつもの感じで進みつつ(使い慣れていないブキでも敵をバシバシ倒していく辺りは流石)、時折トリカラバトルに参加します。
前夜祭では攻撃側だったので、これで両方配信できたことになりますね。
ルールはプレイしながら覚えるといった感じで取り組みつつ、楽しそうな様子が大変良いです☺
あと、私自身は(特に何も考えず)道具派を選んでしまっていたため、のめさんに大活躍して勝ってほしい気持ちと、でもチームの勝利が遠ざかる…という複雑な気持ちで見ていたので、次は合わせようかな、と思ったのは内緒ですw
The Night Way Home | 帰り道
ゲームについて触れる前に、あえて問おう。
どうしてこうなった???www
プレイするのはサバイバルホラーゲーム。
そして傍らに用意したのは世界一まずい飴として有名なサルミアッキと、世界一甘いと言われるグラブジャムン。
ゲームが怖くなったらこの2つを食べて中和しようという、まぁ気持ちはわからなくもないけどやっぱりわからんわごめんという発想により悪魔合体した配信です。
まぁそもそもサルミアッキとグラブジャムンを入手しようとしたきっかけも理解が困難であるため、今更感はあるかもしれませんねww
実際のゲームが始まると、そこはやっぱりホラゲ。
開始早々、なにか良くないことが起こりそうな雰囲気がプンプン漂います。
…が、サルミアッキを食べ始めた辺りから、少なくともリスナーの一人としては、ホラゲの怖さを軽く凌ぐカオスに恐れおののいていましたww
もはや笑っているのか泣いているのか、叫んでいるのか怒っているのか…。
そして世界一甘いというグラブジャムンを食べたのめさんの反応は…?
なお、個人的な一番の見どころはなんと言っても最後ですね。
ゲームの内容と相まって、最高にホラーを感じることができます。
あと結局サルミアッキはどんな味だったのだろうと思いつつ、量が多そうなので試せてはいません( ˘ω˘)
"他人"は見た! 雪餅ののめゲーム配信 4
はじめに
今回はアルセウス、Bendy and the ink machine、スプラトゥーン2の3つを見ました。
任天堂でまとめても良かったかもしれませんが、ボリスさんは放っておけませんからね。
Pokémon LEGENDS アルセウス
ついに来ましたね。
ブリリアントダイヤモンド・シャイニングパールの過去の世界を描いた作品で、従来のポケモンシリーズとは異なるシステムが導入された作品。
私もプレイしましたが、3Dの世界でポケモンたちと一緒に冒険をするこの作品を、のめさんがプレイするとどうなってしまうのか…とひそかに心待ちにしていました。
#1
導入~チュートリアル部分をプレイしていますが、見どころは何といっても最初から最後まで楽しんでいる様子が丸わかりののめさんですw
あまりに楽しそうで反応一つ一つにニヤニヤしてしまいます😊
そして強いネットリテラシーを持つのめさんのこと、主人公の名前を本名とは異なるものにするのですが、これが原因で特にテルくんが怒られまくることにww
お調子者感のあるテルくんはあまり評判が良くなかったりしますが、にしてもこれは不憫www
配信の最後の方で突然現れたウォロさん。
怪しい雰囲気は感じるものの…という場面ですが、まさかの最終決戦みたいなことを言い出すことに。
いや、始まったばかりでその展開は早すぎなんよwww
おそらくメイン任務を進めていくことになると思いますが、どんな展開になっていくのか、この先が楽しみです。
#2
まずタイトルが理不尽で草。本当に草。
チュートリアル部分~セキ・カイ登場辺りをプレイしますが、今回もとにかく楽しそうです😊
本編やポケモンを置いといて素材集めに夢中になったり、初のオヤブンポケモンと遭遇したり、「あ~、あったな~(遠い目)」などと自分がプレイしたときのことを思い出しながら見ていました。
こう、だんだんゲームシステムを理解していくことで、より一層楽しくなっている様子が見られるのは、見ているだけでも本当に楽しいです。
過去に配信で聴いたのめさんの性格からセキさんは苦手かもな~、と思っていたら、登場してそうそうカイさんに対してもドン引きしてて草www
というか、ふと気づけばここまで出てきたレギュラーメンバーの中で、ドン引きしていないのは(態度が柔和な)ラベン博士くらいではwww
そして始まる社畜ムーブ…。某ゲーム配信で合言葉になってしまったあの言葉をもう一度聴くことになるとは思いませんでしたねw
次回が初のキング戦ということに加えて、人間関係もどうなってしまうのか目が離せませんねw
Bendy and the ink machine
最終回です。前回(https://www.youtube.com/watch?v=2Xgzxd-agJI) 連れ去られてしまったボリスさんを無事奪還できるのか???
…という4章と、最後となる5章をプレイしています。
4章は結構ボリュームがあり、結構時間がかかるかなと思っていましたが、サクサク進んでいくのはいつもながら流石です。
4章最後は以前自分でプレイしたときに、この展開は…配信では一体どうなってしまうのだろう…と思っていましたが、プレイ中はいたって冷静な感じで結構驚きました。
が、問題はその後。
気づくべきではなかったかもしれないことに気づいてしまい、一気にテンションダウン…。
完全に惰性で始まった5章も多少苦労はしつつもサクッとクリア。
そしてたどり着いた先は…?
個人的には最後が一番ホラーだった気がしますね。
あと、スマホ版だと日本語翻訳がないため気づいていませんでしたが、妙に砕けた言い回しがクスッときます。
結局よくわからないままだったあれこれは、2周目以降を辿ると判明するのでしょうか。
そして本当の救いは…?
ともあれ、クリアおめでとうございます👏
スプラトゥーン2
もはや説明不要な気もしますが、イカがインクで塗りまくるゲームです(雑)。
実は同タイトルで(飛び飛びとはいえ)長い期間配信しているのはスプラとマリカーくらい? (他は「クリア」が存在するからだと思いますが)
9月にスプラトゥーン3発売、ということもあって最近メン限で練習していたりしていたので、過去配信を見てみることにしました。
初期のスプラ配信はプレイリストが作られています。
私自身はスプラトゥーンをプレイしたことがないため、プレイ内容について評価することは難しいですが、リスナーとのやり取りやネタのような企画があったりと、楽しみどころは多いです。
※スプラトゥーン配信はここで取り上げた以外にもう一つ、視聴者参加型のものがあり楽しそうだったりはしたのですが(海へ帰れは草)、
限定公開になっているためリンクなどを貼り付けるのはやめておきます。
[スプラトゥーン2]もはや初心者よぼよぼスプラ
冒頭からフラグを立てては回収していく様子に涙を禁じえませんww
あと、本来アシストする武器だけど、よくわからないから相手を倒しちゃえば勝てるかな(うろ覚え)は名言www
久しぶり、ということではあるものの、配信前に練習していたということで、割と良い成績だったのではないでしょうか。
[スプラトゥーン2]一時間で何勝できるかな?[新人VTuber]
クリスマスイブの配信ということで、前回ラストの友達話に引き続き、冒頭からリスナーの心をえぐっていますww
あとサンタクロースへのお願い(速達希望)は草
あとコロコロ変わる口調も聞きどころですねw
[スプラ2]激弱初心者(?)が二週間必死で練習した結果wwwwww[新人VTuber]
年明けの配信。とりあえずサムネが美味しそう。
お正月休みの間練習したとのことで、その成果ははてさて…?という内容です。
[スプラ2]初心者がガチマで大暴れ!?(の予定)[新人VTuber]
ユキノメ宅のカーテンが閉じられたら夜という名言?からスタートします。
バレンタインデーが近かったようで、悪気のない?リスナーへの攻撃が光りますww
文字起こしのくだりなど、地味ながら今だとちょっと見られないやりとりも見どころですね( ˘ω˘ )
【スプラ2】イカも動物だし実質あつ森配信だよね【新人VTuber】
あつも…???アッハイ。
バリバリバトルしている最中も、ちょいちょい挟まるネタが素晴らしいwww
あとAランクに上がって喜ぶあたりは、アーカイブながら思わずにっこりしてしまいますね(๑•̀ㅂ•́)و✧
あつ森にしては殺伐としている。。。が、本家あつ森も(のめさん的に)平和じゃなくなったようなので、どっこいどっこいということでw
今まで使っていなかったとある武器も、これから活躍してくれるのか楽しみですね😀
【Splatoon 2】スプラ復刻フェス!マヨしか勝たん!!!【VTuber】
フェス復刻!と喜ぶのめさんの様子が一番の見どころです(断言)。
マヨネーズ VS ケチャップ でマヨネーズ派ということなのですが、その理由は…。
健康上問題ない程度にしてもろて…。
リスナーとのやり取りのせいか、すごく練習してる感というか、部活感が感じられたりします(個人の感想です)。
あと乾いた「ははは」も良いです👼
【スプラトゥーン2】夏だ!祭りだ!!ニワトリだー!!!【VTuber】
5ヶ月ぶりということで、操作方法を思い出すところからスタートですw
ニワトリかわいい。
ニワトリ卵の話でニワトリが虚無から生まれていたら…と思うとちょっと吹いてしまいましたw
当然ながらプレイするのはスプラトゥーンなわけですが、イベントのためかステージの色遣いなどがいつもと違ってだいぶ雰囲気が変わりますね。
【スプラ2】負けたら語尾が変わるタイプのイカ(新種)【VTuber/ユキノメ】
タイトル通り負けたら語尾が変わる、とのことですが、何故か語尾が3つ付いたり???リスナーも語尾変えに参戦したり???と冒頭からカオスww
ロリ餅になったり叫んだり暴言が入ったり、しまいには趣旨がどっかいったりwww
あとゲームには関係がないですが、(2022年8月12日時点で)約9ヶ月前と時期が近いためか、コメント欄とのやり取りなど私がのめさんを知った頃(2022年4末)に近くて、懐かしいなぁ…と思いながら見ていました。
ついでに、アカウント名の「やる気はあります」はこの頃にはつけられていたのですねw
【スプラ2】雪餅が相手を倒すとこ見てて…【雪餅ののめ/VTuber】
「雪餅ののめ」になって初の(そして今のところメン限を除くと唯一の)スプラ配信です。
今となっては幻のハリボテ時代の配信ですね。
悲鳴あり暴言ありリスナーとの掛け合いありと、ゲーム内容以外にも楽しむ要素がたくさん(๑•̀ㅂ•́)و✧
5ヶ月経過しているとはいえ、やっぱりユキノメ時代とは(どこがどう、とは言いづらいですが)違うんだなぁと感心しながら見ていました。
9月にはスプラ3も発売ということで、これからも楽しみがいっぱいですね✨
"他人"は見た! 雪餅ののめゲーム配信 3
はじめに
今回は意図せずホラゲが多くなりましたね。
夜廻三
#3 の続きです。
再生リストも作ってくれているので、全体を通してみたい方はこちらからがよさそうです。
今回は #4 ~ ラストまで。
物語も中盤をすぎていよいよ佳境へ。
思い出から少しずつ明らかになる事実と深まっていく謎。
一体どんな結末を迎えるのか…。
#4
まず見どころは、冒頭のあらすじの中で自身でクモの話題を出しながら、一気にテンションが下がる様子ですねwww。
♯2 の様子から、本気で苦手なのはわかるので可哀そう…と思う反面、どうにも笑いも出てきてしまうという(大変申し訳ございません)。
今回は海の方へ行きます。そこで出会うボスは、攻撃範囲が広いため個人的にはここまで出てきたボスの中で一番派手でしたねww
あと、ボスの見た目や攻撃の様子から、色々なものとして扱われてしまうというコメント欄とのやりとりも見どころw(逃げながらやるの、相変わらずすごいです)
前回までもそうですが、思い出を取り戻す時に登場する幽霊たちは、何となくどんなことがあったかを察することしかできないため、本当はどうだったんだろう…、と少しモヤモヤが残りますね。
とはいえ、一番大事なすずき(主人公)の思い出も、終盤なのに全く全体像が見えない、というか矛盾があちこちにあったりして、一体どんな結末になるのか…と気になったまま次回に続きます。
最終回
いよいよ最終回。残った一つのキーアイテムと、二つの思い出探しから。
が、冒頭からゲーム本編とは全く関係ないところでピンチがwww(無事でよかった)
そして一つ目の思い出探しでは冒頭からマシンガントーク・クモ怖い・(珍しくお化けに対する)悲鳴・バカがのモリモリスタートw
二つ目はとあるきっかけでテンション爆上がり + その良さについて語るタイムが。……楽しそうで何よりです( ˘ω˘ )
※配信内でも言及がありますが、集合体恐怖症の方は有志の方がタイムスタンプをつけてくれているので、無理そうならそちらも活用すると良いかと。
そんなこんなで無事思い出をすべて取り戻し、ラスボス?を倒してやった~クリアだ!…と思いきや、衝撃のどんでん返しが。
ここから始まる伏線回収は本当にぞくぞくします(集合恐怖症とは別の意味で)。
そして唐突に明かされる真実…。
ここからエンディングへ向けて物語は進んでいくわけですが、とある事柄について、うすうす想像はついていながらも、「そんなことないよね?」と必死で抗う、半ば悲鳴のようなのめさんの言葉が胸に突き刺さります。
そしてそんな思いを吹き飛ばすかのようなハード(難易度)なゲーム展開が。
ここから配信者、リスナーともに翌日の睡眠不足を賭けた戦いがスタートwww
悲しみを吹き飛ばそうという日本一ソフトウェアさんの優しさ…な訳はないなw
長時間の上に集中力を要求されるプレイで、本当によくクリアしました👏👏👏という気持ちです。
ついにたどり着いたエンディング…ですが、「クリアおめでとう!!!」という気持ちにはとてもなれませんでした。。。
悲しい、けど、この物語を知ることができて本当に良かったと思います。
あらためてクリアお疲れ様でした(`・ω・´)ゞ
Bendy and the Ink Machine
1930年代のカートゥーンアニメ製作スタジオを舞台とした、探索や謎解きがメインのホラーゲーム…とのこと。
7/15 に #1 が配信されたばかりのゲームです。
配信では Steam 版をプレイしていますが、スマホ版もあったため私もプレイしています。
(配信リアタイ勢とはいえ、ネタバレとのバランスが難しいw)
#1
冒頭の雪餅英語にニヤニヤしながらスタート。
まず目をひくのはそのグラフィック。
カトゥーンアニメをテーマにしているためか、2Dっぽい見た目を3Dで表現しているため、他のゲームとはひと味違う印象を受けます。
舞台となる時代性なのか、労働環境には若干気になる点が見受けられますねw
WORK HARD WORK HAPPY
終わり際の武器を手にしたのめさんの嬉しそうさがヤバいwww
まさかいつも聞いているあの言葉の意味が代わってしまうとは…www
ゲームの内容とは別の狂気がすばらしいです(白目)
#2
Chapter2から…なのですが、ほぼ完全にボリスさん回ですwww
前回もその片鱗は見せていたものの、やはり動いている姿というのは別格。
ということなのでしょう。知らんけど( ˘ω˘)
また前回のダーツもそうでしたが、実はビリヤードもプレイできたりします(少なくともスマホ版では)。
ピアノやオルガンなどの楽器もいくつか音が出たりと、本編に関連する部分以外もかなり細かく作られている印象を受けました。
…というのは配信でなくゲーム自体の話ですが。
レコーディング中と分かった時の反応や WORK HARD WORK HAPPY への態度、子守歌などちょいちょい見どころはありつつも、その後のボリスさん登場ですべてがふっとびましたねwww
楽しそうで何よりです( ˘ω˘ )
そして「9階」とは。。。(´・ω・`)
最後も中々の展開で、次回(ラストらしいです)が気になるところです。
【非公式】シンジ、エヴァに乗れ乗るな乗れ乗れ帰れ乗れ乗るな乗れ帰れ乗れ冬月に乗れゲーム
これを扱うべきかどうか(ゲーム配信とするか)はちょっと迷うところですがw
雑談に挟まって 【非公式】シンジ、エヴァに乗れ乗るな乗れ乗れ帰れ乗れ乗るな乗れ帰れ乗れ冬月に乗れゲーム をプレイしています。
いまや貴重になってしまった名前呼びの「う~」や冒頭からリスナーを刺しまくる様子、直近のコラボの話を堪能したのち48分くらいからゲームがスタートします。
ここでの見どころは、なんといってもバカゲーに大爆笑するのめさんですねw
ゲームの内容は言われた動作を記憶して再現する、というもので、だんだん難しくなっていくのですが、終始楽しそうで何よりです( ˘ω˘ )
後半の雑談はチャンネル登録者3000人、4000人突破(おめでとうございます👏👏👏)の記念配信の内容を話しています。
いつどんな形になるかはわかりませんが、これからも楽しみですね。
Dark Deception
Dark Deception は不気味なホラー迷路アドベンチャーゲーム、だそうです。
怪物から逃げつつ「ソウルシャード」を集めて悪夢の源「リングピース」を入手し、脱出する、という内容。とのこと。
プレイリストはこちら
[ホラゲ]凶悪サルからビビりオオカミは逃げ切れる?[新人VTuber]
Poppy Playtime -> と配信的に逆走したためよくわかっていなかったのですが、基本英語しかない場合は細かいストーリーをすっ飛ばしていく感じなのねw
なんて?みたいな表情も良いw
あと、最初でおサルに捕まりまくっているのにこの落ち着きっぷりは何www
(どうも直前にプレイしていたゲームの影響らしいw)
そして最後にわかる衝撃の事実www
ゲームの難易度、最初からこれで大丈夫だろうか…と思ったら想定内だったようで、むしろ予想外のサクサクプレイで別のゲームが始まってしまうことに…。
コラボでおなじみのゲームを一人でプレイする、シュールな雰囲気で幕を閉じますw
[Dark Deception]合法的に幼女と鬼ごっこできるらしい[新人VTuber]
今度は学校で女の子と追いかけっこです。
おサルのようにただ追いかけるだけでなく、ワープ能力も使ってくるということで若干苦戦はするものの、リングピースを手に入れるところは比較的サクサクとクリアしていてすごい。
まさかその後に困難が待ち受けているとは思いませんでしたねwww
あと、やっぱりホラゲーっぽくはないww
[Dark Deception]海賊コスおじさんとだるまさんが転んだ[新人VTuber]
今回からオープニング復活w
海賊コスプレのおじさんとの戦いですが、ここからだるまさんが転んだ方式(プレイヤーが敵の方向を向いていないときだけ止まる)になります。
新しく手に入れた能力、追加された罠や逃げ方などのチュートリアル的なステージから開始。
敵の方向を向いている間は止まる、という点は前より楽になったものの、そうでないときの移動速度がこれまでの比ではないため、どう誘導するかなどかなり頭を使わないとクリアできない印象。
あと、おじさんおじさん言うおかげで捕まりたくない気持ちが倍増してしまう…。
色々試行錯誤するも次回へ続きます。
【Dark Deception】鬼から逃げ続けるタイプのだるまさんが転んだ【VTuber】
なぜかチュートリアル部分からリスタート。
さっき(前回)のは夢だったんだ…ってコト?
しょっぱなから雄たけびが…とはいえ、操作方法を思い出すという意味ではそこまで悪くなかったのかもしれない。
クリアできそうでできない…というもどかしい状態に悲鳴と疲れた笑い声が響き渡る…。
惜しいところまでいきながらも次回へ続く…。
【Dark Deception】もう海賊おじさんがラスボスでいいよ…【VTuber】
三回目の挑戦でついに!!!…なのですが、予想外の展開にwww
次回の予定だったというサムネ、結局公開されたのでしょうか…。
ちょんママによるサムネ評も草…ではありますがそれで良いのか…w
【Dark Deception】テーマパークに来たみたいだぜ。テンション上がるなあ~!【VTuber】
(サムネ上は)今回からChapter3。
これまで登場したお猿たちが冒頭に登場し、ちょっとテンション上がったりします。
クリアの難易度としては海賊おじさんほどではないためか、ホラゲにあるまじき?落ち着きっぷりなのですが、ちょくちょくエリアが虹色に光ったりして目が痛いので苦手な方は注意が必要かもしれませんね。
【Dark Deception】狼が美人ナースに負けるわけがない【VTuber/ユキノメ】
リリース待ちにより前回から少し期間が空いての Chapter4 です。
タイトルに反して冒頭から負けそうになっているのですがそれは…w
そして(今回に限ったことではないですが)キャラクターの話す英語はことごとく押しつぶされるので、完全に雰囲気のみでスタートしますww
期間が空いたためなのか、ステージのテイストがちょっとこれまでと違う感じです。
今回の難しさは敵がどう攻撃してくるのか、どうすればクリアできるのかがわかりづらいことで、何度も繰り返しを重ねながら最後まで到達することになります。
無事クリアした後は、アップデートによってこれまでのステージにも変化があったということでその様子を見に行くのですが…。
ある意味衝撃的なラストまで見どころが多いですね。 Dark Deceptionさんもお疲れ様です(`・ω・´)ゞ
【Dark Deception】ウサギに負ける狼、おる??wwww【VTuber/ユキノメ】
Chapter4 二つ目はテーマパーク?が舞台。今回はウサギ・トリ・ブタたちが相手です。
場所柄か相手が動物だからか、過去一テンションが高く、そして罵倒が多いですww
その手の癖をお持ちの方、痩せたい方におススメですwww
あと Chapter4から?ゲームオーバーしても集めた SHARD が減らない代わりにその後のボス戦がより難しくなった印象。
また話が進んできた、ということなのか、ステージクリア後に物語全体に関わる展開があったりするため、そちらも見どころですね。
【Dark Deception】子連れのクマが一番ヤバいって知ってる?【VTuber/ユキノメ】
Chapter4 のラスト。
今度はクマの親子が相手です。
またもやこれまでとは違った戦い方に戸惑いながらも、着実に次に進めていきます。
ここにきてようやくホラゲであることを思い出したり、マリオの砂漠面はあまり好きでないことを思い出したりします。
終盤の禍々しい紫色の世界が美しかったりもします。
2022年7月時点での Dark Deception 配信はここまでですが、Chapter 5 がリリースされればまた続きをプレイしてくれるのではないかと思います。
"他人"は見た! 雪餅ののめゲーム配信 2
はじめに
今回も直近で見た雪餅ののめさんのゲーム配信について、つらつらと書き残していくことにしますよ。
夜廻三
#2の続きです。
前回からちょっと間が空いたということもあってこれまでのあらすじ…に混じった「わ~」からスタートw
ホラゲー(正確にはホラゲーではないらしいですが)でも、作品によって悲鳴や喋りの入り方も違ってくるのが面白いなぁと思ったりw
大ピンチで逃げまとう中リクエストしてくる曲のチョイスと、ネタバレはダメといいつつ天敵のヤツが出てくる場所だけは躊躇なくコメント欄に聞いていく様子は流石に笑わざるを得ないww
男女や動物のお化けが登場しますが、それぞれ辛い過去が示唆されますが、主人公の思い出を取り戻すきっかけになることとは関係があるのでしょうか…?
とか考えていたら、ボス戦の興奮っぷりにどうでも良くなってきましたww
楽しそうなのは良いとして、それまでの流れは吹っ飛びましたねw
最後のお姉さんとの記憶で深まる謎が解ける日は来るのか…まだまだ続きが気になりますね。
アンリアルライフ
前回の続きから。
たどたどしいあらすじと、床屋さんの前にあるアレの名前をものすごく嬉しそうに教えてくれるところからスタートw
ふんわりとした情報を元に幻想図書館を目指すハルと195。
レベルの上がった謎解きに心折れそうになるなど、様々な困難が襲い掛かります…(諦めないでくれてよかったw)。
なお前回大活躍だったエビの衝撃の事実が判明。そりゃみんな夢中になるはずだよ...w
図書館の最後で明らかになったいくつかの事柄や、ハルが新たにできるようになったこと、消えた本などまた気になるラスト…。
それはそれとして、図書館で見つかりまくり、悲鳴をあげまくるのめさんには大変申し訳ないと思いつつ笑ってしまいましたwww
あと、途中に出てくる友達の定義により、改めて私に友達がいないことが明ら(消滅)
Poppy Playtime
3Dサバイバルホラーゲームだそうです(詳しくは下記リンク参照)。 2022年6月現在Chapter2まで配信されており、今後続きが配信され次第(Chapter1からChapter2が出るまでの期間は半年くらいとのこと)、続きも配信されることになるハズ。
Chapter1
配信当時はのめさんがプレイしたい、という話だけで微塵も調べてなかった+日本語版無し+英語字幕も無し、ということで、 とりあえず古びたおもちゃ工場から逃げようとする、というくらいしかストーリーがわからないまま見てましたwww
珍しくのめさんが英語を話す(読む)様子も見られます( ˘ω˘ )
謎解きをしながら進めていくのですが、大まかな概要はともかく、ストーリーをそこまで深く理解はしていなさそうながら割とサクッとクリアしていくのはすごいです。
あと、現在進行中のゲーム配信中、ダントツににぎやかで、ボス戦とかこんなに楽しそうにプレイするものだったのかwww、というのも見どころ。
ひどい目に遭い勝ちなブギーボット君は、今後何かのキーを握ることになるのか、単に生贄になってるだけなのかw
Chapter2
相変わらずにぎやかで楽しそうです。…ホラゲですがw
Chapter1よりレベルアップした謎解きですが、サクッと解いていてすごいのは変わらず。 (上手くいかなかったときに出る「は?」好き)
中ボス?的なステージがいくつかあり、覚えるのが大変、敵が見えづらいなどのハードルにより苦戦する場面も…。
とはいえ最後にはバッチリクリアして次の場所へ。
途中で助けてくれたおもちゃは今後どう関わってくるのか、最後(次のChapterへの伏線)も何がどうなったのか気になって夜しか眠られませんね。
あと、ほぼゲーム自体には関係ありませんが、序盤に出てくるもふもふへのこだわりも聞きどころ…かもしれないw
マリオカート
のめさんの配信では珍しい?、視聴者参加型の配信です。
それが原因なのか、いろんなものを賭けたり大物?が参加したり地獄が生まれがちなところが魅力ですねw
[マリオカート8DX]クリスマス、リア充爆破してみたくないですか?[新人VTuber]
クリスマスなのでリア充を爆破する配信です。
何を言っているのかわからねーと思うがry
YouTubeのアーカイブでは最初のマリカー配信がこれ、というのがらしいというかなんというかw
ボム兵でオンライン対戦に集まってきたリア充?を爆破しまくるはずが…。
意図せず大物(大体偽物)コラボも実現したりとリアルかどうかは置いといて、楽しそうなクリスマスですね( ˘ω˘ )
[マリカ8DX]7位以下で黒歴史暴露!?地獄のマリオカート[新人VTuber]
あえて言おう。どうしてこうなったww
とにかく必死感がすごく、2022年6月時点で残っているマリカーアーカイブ中ダントツなのではw
果たして暴露された黒歴史とは…?
なお、個人的にはその内容自体より、のめさんの反応が良かったです( ˘ω˘ )
[マリオカート8DX]七位以下で即終了!ま、一時間は余裕かな~~~![新人VTuber]
タイトルと配信時間がすべてを物語っていますねwww
[マリオカート8DX]リベンジじゃなくて普通に走るか…[新人VTuber]
さっきのは夢だったんだ…。
ということで、タイトル通り即終了ではなく落ち着いて雑談しながらみんなでマリカー。
てぇてぇ哲学とちょいちょい出る言い訳のめさんが個人的見どころだと思います( ˘ω˘ )
【参加型/マリカ8DX】初見さんOK!みんなで楽しく殴り合い【VTuber/ユキノメ】
久しぶりだったようで、操作の仕方を思い出すところからスタートw
今回は特に何かを賭けたりせず、みんなで仲良くバチボコ殴りあっています(๑•̀ㅂ•́)و✧
やっぱり「わ゛~」好き。
【視聴者参加型|マリカ8DX】追加コース第一弾!ここで王になる【雪餅ののめ/VTuber】
「雪餅ののめ」になって初のマリカー配信。
と同時に、Live2D解禁の条件であった、チャンネル登録者数2500人突破を達成した記念の配信でもあります。
が、マリカー自体は特に忖度されることもなく、操作方法を覚えていない、とある意味いつも通りなのは流石というべきかw
ユキノメ時代との配信スタイルの違いもちょっとした見どころかもしれませんね。
あとコメント見ながら+喋りながらマリカーとか、ツイートしながらマリカーとか、常人離れ技も流石ですww
みんなのリズム天国
【みんなのリズム天国】ノれるやつだけ着いてきな!!!【VTuber】
みんなのリズム天国シリーズ。
ひたすらリズムをとるのめさんがかわいい配信。 ねじ締めの時の「ヨッシャ」とか、南極の揺れ感とか好き。
あと、工場ではほんのりブラックな香りも漂ってきて、やはりゲームの中でも…(;゚д゚)ゴクリ… となったりならなかったりw
過去作もやりこんでいる(らしい)だけあって、基本ハイレベルでサクサク進んでいきます(すごい)。 が、やっぱりヤツの登場で一気に(気持ち的に)ピンチになるのは何ともwww
【みんなのリズム天国】サクッとヘブンにGO【VTuber】
前回の続きである 8th ~ 10th に挑戦。
タイトル通りサクッと終わりすぎて本人もびっくりw
とはいえ、流石に前回より難易度は上がっている、ということで、ク〇がよ~も飛び出したりしますw
【はじめての方向け】リストにも含まれている配信ですが、続きだけあってリズム天国自体の説明や練習部分は省かれています(8th ~ 10th には基本的に練習がない)。
ということで、私のようにリズム天国をあまり知らない方は、最初から見る方が良いかもしれません。
逆に、リズム天国は知っていて、サクッとのめさんのプレイを見たい方はこちらをおススメしておきます。
【みんなのリズム天国】目指せオールパーフェクト!!!【VTuber】
All perfect 耐久!ということで全50ステージをノーミスでクリアしていく、という配信。
流石の長時間ではありますが、実は大部分は一発クリアしてたりしてすごい。
ねじ締めの時の「ヨッシャ」「ヤッタ」は相変わらず好きなのですが、本人も得意なのかサッとクリアされてしまうので、ちょっと寂しくはありますw
しかしながら、やはり10th Remixは鬼門…。
休憩がてら告知ツイートの文面をどうするかの話をしたりするあたり、バックステージを覗いている感じで楽しいですね。
【みんなのリズム天国】のんびりまったりノリノリお遊び【VTuber】
無事APクリア!ということで、クリア後に解禁されるミニゲーム?をまったり遊ぶ配信。
数年越しの謎が解けたり、説明もなくよくわからないままクリアしてみたり、耐久配信の打ち上げのような雰囲気がありますね。
"他人"は見た! 雪餅ののめゲーム配信 1
はじめに
北の狼VTuberこと雪餅ののめさんの配信を見始めて早一か月。
ユキノメ時代も含めたアーカイブをいくつか見たので、思ったこと(感想)をつらつら書いていくことにします。
(Twitterに書こうかと思ったけど書ききれんしスレッドにしていくのも面倒なんよね。。。)
本当は見たことない人のために、「~な方におススメです」みたいなことを書きたいけれどもそれは他の方にお任せします( ˘ω˘)スヤァ
なお雑談に定評のあるのめさんですが、ゲーム配信の同接も増えるといいよね、ということでゲーム配信を取りあげることにします。
あと完結してシリーズとしてまとめられているものは一括で書く予定で、書く順番はこの一か月で見たものになるのでバラバラです(あとで見直して個別で書いたりはするかもしれませんが)。
ちなみに家〇婦は見た!は一度も見たことありません( ˘ω˘)スヤァ
アンリアルライフ
感想は一部Twitterに書いたのでそちらを貼り付け。
ふと見返したら、枠取り直しでテンパってたり、BGMに気づかないリスナーとか、想像以上にカオスw
— M.Masanori(ハダカデバネズミ) (@masanori_msl) May 25, 2022
ちょいちょい入るのめさん話も気になるしw
本編は不穏な空気が見えたり、195が「知らないこと」にも意味がありそう。最後の追いかけっことか色々気になる #アンリアルライフhttps://t.co/MPsnYnXnVl
あと、ドット絵ながら(だから?)世界がとてもきれいで、途中に出てくる海の景色などとても良い。
あの青色が良いんだよなぁ~(語彙力)。
まだ先日始まったばかりなので、ここから合流するのは良いかもですね。
夜廻三
こちらも現在進行形の配信。
#1
陰鬱としたいじめの現場から始まる…のですが、すずき(主人公)が強すぎて、もしもっと自由に行動させられるシステムなら格ゲー始まっちゃう…(´・ω・`) という心配からスタートwww
お化けに対する独特な評価があったり、すずきが小学校?中学校?の女の子なためかおかん餅あるいはお姉餅があったり。
あとびっくりはしたけどガチ悲鳴ではないくらいのときの「わ~~~~」好き。
ついでに本編には一切関係ないけど、ゲーム配信としては貴重な?ハリボテ時代の配信。
#2
Live 2D解禁ということもあって、主人公の名前を忘れたり、ロリボイスを披露してみたり、青ざめてみたりと小ネタがw
最初のボス戦を経たためか基本のプレイはスムーズになったものの、難易度が上がってきた印象。
しかし、まさかお化けに(びっくりはしても)動じないのに、驚かしと思われるヤツが出た途端にこの2回で最大の悲鳴+テンション激下がりになるとはゲーム制作側も思ってなかったでしょうねwww
あとリズム刻んでるっぽい音がするたびに乗っていくの好き。
少しずつ集まる思い出はどういう形になっていくのか、お姉さんと主人公はそれぞれどうなっていくのか。 今後も気になりますね。
空気読み3
特大級のフラグを立てて始まった気がする空気読み。
空気読むどころか状況がわからずいつの間にか終わってたり、空気を読んだ上であえて無視したり、煽り餅さんとか本人の意向はともかくカオスで大変素晴らしいw
あとニュートン的な人の時の、フリフリ餅さんは空気読めてたかどうかはさておいて100点です(๑•̀ㅂ•́)و✧
ポケットモンスター シャイニングパール
リメイク前のダイパをプレイしたことがある、ということで、ネタバレどころかリスナーより豊富な知識でサクサク進む。
以前ダイパ自体が初めて、という方の配信も見たことがあったのですが、どちらもそれぞれ良いですね。
自他ともに評価の高い?ネーミングだったり、他のソフトのプレイデータがあると発生するイベントをチート呼ばわりしたりwww
ある意味衝撃のラストまで、見どころが多いです(๑•̀ㅂ•́)و✧
あと時々暴発するポケモン愛は、アルセウスをプレイしたときどうなってしまうのか…。
ふぁ…大変楽しみですね。
Detroit:Become Human
おススメの配信、ということでよく名前にあがる作品。
技術が進歩して、人間そっくりのアンドロイドが人に代わって働かされている世界を舞台に、激動の時を3人の主人公を軸にプレイしていく。
重いテーマながら、プレイする当人はそんなでもなさそうだったり、百合展開にワクついたり、終盤の拾ったチケットの扱いを即決するところなど、(私の思う)のめさんらしいと感じました。
ゲームはマルチエンディングではありますが、グラフィックがきれいで映画みたいなこともあって、他の分岐を見るためにやり直したくはない、という気持ちはよくわかります。
あと登場人物としてはやっぱりコナーとハンクのコンビが素晴らしい。
ベタかもしれないけど、最後の展開は熱い!
おわりに
この方に限らないですが、ゲーム配信の魅力はゲーム自体はもちろん、プレイ中の選択や話される内容にプレイヤー(配信者)が表されるところだと思います。
雑談も良いのだけど、ゲームの世界だからこそ見える側面があるかと。
ということで、今後も雑談、ゲーム配信のどちらも期待しています(`・ω・´)ゞ
【ASP.NET Core】【EntityFramework Core】【C#】 .NET 5 から .NET 6 に更新する
はじめに
これは C# Advent Calendar 2021 カレンダー2の15日目の記事です。
祝 .NET 6 リリース👏 ということで、手元にあった ASP.NET Core + EntityFramework Core(DB は PostgreSQL) のプロジェクトを更新してみました。
環境(更新後)
- .NET ver.6.0.101
- NLog.Web.AspNetCore ver.4.14.0
- Npgsql.EntityFrameworkCore.PostgreSQL ver.6.0.1
- Microsoft.EntityFrameworkCore ver.6.0.1
- Microsoft.EntityFrameworkCore.Design ver.6.0.1
- Newtonsoft.Json ver.13.0.1
- Microsoft.AspNetCore.Mvc.NewtonsoftJson ver.6.0.1
- Microsoft.AspNetCore.Identity.EntityFrameworkCore ver.6.0.1
ASP.NET Core を更新する
必須の作業
global.json (ある場合) と .csproj のバージョンを更新するだけです。
ApprovementWorkflowSample.csproj
<Project Sdk="Microsoft.NET.Sdk.Web"> <PropertyGroup> <TargetFramework>net6.0</TargetFramework> <Nullable>enable</Nullable> <ImplicitUsings>enable</ImplicitUsings> </PropertyGroup> <ItemGroup> <PackageReference Include="NLog.Web.AspNetCore" Version="4.14.0"/> <PackageReference Include="Npgsql.EntityFrameworkCore.PostgreSQL" Version="6.0.1"/> <PackageReference Include="Microsoft.EntityFrameworkCore" Version="6.0.1"/> <PackageReference Include="Microsoft.EntityFrameworkCore.Design" Version="6.0.1"/> <PackageReference Include="Newtonsoft.Json" Version="13.0.1"/> <PackageReference Include="Microsoft.AspNetCore.Mvc.NewtonsoftJson" Version="6.0.1"/> <PackageReference Include="Microsoft.AspNetCore.Identity.EntityFrameworkCore" Version="6.0.1"/> </ItemGroup> </Project>
ついでに「ImplicitUsings」を有効にしておくと、「using System;」などを省略できるようになります。
.NET 6 っぽくする(任意)
ASP.NET Core ではこれまで Program.cs(メインクラス)、 Startup.cs(ミドルウェアの設定など) を中心に処理が書かれていました。 .NET 6 で新規プロジェクトを作ると、 C# 9 で導入された トップレベルステートメントが適用され、下記のような Program.cs が作成され、 Startup.cs の内容が統合されます。
Program.cs(新規プロジェクト)
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddControllersWithViews();
var app = builder.Build();
// Configure the HTTP request pipeline.
if (!app.Environment.IsDevelopment())
{
app.UseExceptionHandler("/Home/Error");
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseRouting();
app.UseAuthorization();
app.MapControllerRoute(
name: "default",
pattern: "{controller=Home}/{action=Index}/{id?}");
app.Run();
これに倣って、 Program.cs に統合してみました。
Before
Program.cs
using System;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.Logging;
using NLog.Web;
namespace ApprovementWorkflowSample
{
public class Program
{
public static void Main(string[] args)
{
var logger = NLogBuilder.ConfigureNLog("Nlog.config").GetCurrentClassLogger();
try
{
CreateHostBuilder(args).Build().Run();
}
catch (Exception ex) {
logger.Error(ex, "Stopped program because of exception");
throw;
}
finally {
NLog.LogManager.Shutdown();
}
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
})
.ConfigureLogging((hostingContext, logging) =>
{
logging.ClearProviders();
logging.SetMinimumLevel(LogLevel.Trace);
})
.UseNLog();
}
}
Startup.cs
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.Identity;
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using ApprovementWorkflowSample.Applications;
using ApprovementWorkflowSample.Models;
using Microsoft.AspNetCore.Components.Authorization;
using Microsoft.AspNetCore.Components.Server;
using ApprovementWorkflowSample.Approvements;
namespace ApprovementWorkflowSample
{
public class Startup
{
private readonly IConfiguration configuration;
public Startup(IConfiguration configuration)
{
this.configuration = configuration;
}
public void ConfigureServices(IServiceCollection services)
{
services.AddRazorPages();
services.AddServerSideBlazor();
services.AddHttpClient();
services.AddControllers()
.AddNewtonsoftJson();
services.AddDbContext<ApprovementWorkflowContext>(options =>
options.UseNpgsql(configuration["DbConnection"]));
services.AddIdentity<ApplicationUser, IdentityRole<int>>()
.AddUserStore<ApplicationUserStore>()
.AddEntityFrameworkStores<ApprovementWorkflowContext>()
.AddDefaultTokenProviders();
services.AddScoped<IHostEnvironmentAuthenticationStateProvider>(sp =>
(ServerAuthenticationStateProvider) sp.GetRequiredService<AuthenticationStateProvider>()
);
services.AddScoped<IApplicationUsers, ApplicationUsers>();
services.AddScoped<IWorkflows, Workflows>();
services.AddScoped<IApplicationUserService, ApplicationUserService>();
services.AddScoped<IApprovementService, ApprovementService>();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseStaticFiles();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapBlazorHub();
endpoints.MapControllers();
});
}
}
}
After
Program.cs
using ApprovementWorkflowSample.Models;
using ApprovementWorkflowSample.Applications;
using ApprovementWorkflowSample.Approvements;
using Microsoft.AspNetCore.Components.Authorization;
using Microsoft.AspNetCore.Components.Server;
using NLog.Web;
using Microsoft.AspNetCore.Identity;
using Microsoft.EntityFrameworkCore;
var logger = NLogBuilder.ConfigureNLog("Nlog.config").GetCurrentClassLogger();
try
{
var builder = WebApplication.CreateBuilder(args);
builder.Host.ConfigureLogging(logging =>
{
logging.ClearProviders();
logging.AddConsole();
})
.UseNLog();
builder.Services.AddRazorPages();
builder.Services.AddServerSideBlazor();
builder.Services.AddHttpClient();
builder.Services.AddControllers()
.AddNewtonsoftJson();
builder.Services.AddDbContext<ApprovementWorkflowContext>(options =>
options.UseNpgsql(builder.Configuration["DbConnection"]));
builder.Services.AddIdentity<ApplicationUser, IdentityRole<int>>()
.AddUserStore<ApplicationUserStore>()
.AddEntityFrameworkStores<ApprovementWorkflowContext>()
.AddDefaultTokenProviders();
builder.Services.AddScoped<IHostEnvironmentAuthenticationStateProvider>(sp =>
(ServerAuthenticationStateProvider) sp.GetRequiredService<AuthenticationStateProvider>()
);
builder.Services.AddScoped<IApplicationUsers, ApplicationUsers>();
builder.Services.AddScoped<IWorkflows, Workflows>();
builder.Services.AddScoped<IApplicationUserService, ApplicationUserService>();
builder.Services.AddScoped<IApprovementService, ApprovementService>();
// DI の設定など、 builder.Services への処理が終わったあとに実行する必要がある.
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseStaticFiles();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapBlazorHub();
endpoints.MapControllers();
});
app.Run();
}
catch (Exception ex) {
logger.Error(ex, "Stopped program because of exception");
}
finally {
NLog.LogManager.Shutdown();
}
- これまで DI で取得していた、「IConfiguration」などは、「WebApplicationBuilder」から取得できます。
- コマンドライン引数は「args」で取得できます。
- DI の設定など「builder.Services」に対する設定は、「builder.Build();」実行より前に行う必要があり、逆にすると実行時に例外が発生します。
コマンドライン引数など、暗黙の部分があったりする部分は気になるものの、全体を見るとシンプルになった気がします。
- エントリー ポイント - C# によるプログラミング入門 - ++C++; // 未確認飛行 C
- Announcing .NET 6 — The Fastest .NET Yet - .NET Blog
- What's new in ASP.NET Core 6.0 | Microsoft Docs
- Comparing WebApplicationBuilder to the Generic Host: Exploring .NET Core 6 - Part 2 | Andrew Lock
- Logging in .NET Core and ASP.NET Core | Microsoft Docs
EntityFramework Core を更新する
以前もそうだった気がしますが、更新の影響は EntityFramework Core の方が大きい気がします。
今回は Npgsql で日付型の扱いが変わった、というのが特に大きそうです。
ApplicationUser.cs
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
using Microsoft.AspNetCore.Identity;
namespace ApprovementWorkflowSample.Applications
{
public class ApplicationUser: IdentityUser<int>
{
...
[Required]
[Column("last_update_date", TypeName = "timestamp with time zone")]
public DateTime LastUpdateDate { get; set; }
...
public void Update(string userName, string? organization,
string email, string password)
{
UserName = userName;
Organization = organization;
Email = email;
// ハッシュ化されたパスワードを設定する.
PasswordHash = new PasswordHasher<ApplicationUser>()
.HashPassword(this, password);
// このあと context.SaveChangesAsync() を実行すると例外発生
LastUpdateDate = DateTime.Now;
}
...
}
}
例外
InvalidCastException: Cannot write DateTime with Kind=Local to PostgreSQL type 'timestamp with time zone', only UTC is supported. Note that it's not possible to mix DateTimes with different Kinds in an array/range. See the Npgsql.EnableLegacyTimestampBehavior AppContext switch to enable legacy behavior.
TimeStamp はタイムゾーン有・無にかかわらず C# 側は DateTime で良いのですが、UT でなければ例外が発生します。
ApplicationUser.cs
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
using Microsoft.AspNetCore.Identity;
namespace ApprovementWorkflowSample.Applications
{
public class ApplicationUser: IdentityUser<int>
{
...
[Required]
[Column("last_update_date", TypeName = "timestamp with time zone")]
public DateTime LastUpdateDate { get; set; }
...
public void Update(string userName, string? organization,
string email, string password)
{
...
// OK
LastUpdateDate = DateTime.Now.ToUniversalTime();
}
...
}
}
今回更新したプロジェクトでは使っていませんでしたが、 PostgreSQL 側が 「date」 の場合は新たに追加された 「DateOnly」 型になる、といった点が主な変更となりました。
なお、上記の例外は DB にデータをインサートする、アップデートする際に発生するため、参照だけなら(それでも変更はしておいた方が良いと思いますが)そのままでも何とかなりそうです。
【Blazor Server】【ASP.NET Core Identity】カスタムユーザーでサインインしたい
はじめに
今回はいつぞやに試した、 ASP.NET Core Identity のカスタムユーザー(プロパティから電話番号などを外すとか)を使って、Blazor Server のページからサインインしてみることにします。
バージョンが古いので今と違っているところもあるかと思いますが、その辺りは GitHub のサンプルを参照して、ということで。。。
Environments
- .NET Core ver.5.0.102
Samples
過去記事
- 【ASP.NET Core】Blazor を試す (Blazor Server)
- 【ASP.NET Core】【Blazor Server】SPA を試す
- 【Blazor Server】【ASP.NET Core】CSS isolation と MapControllers
- 【Blazor Server】ここんぽーねんとで遊びたい
サインイン
SignInManager でサインイン(失敗)
以前試した通り Blazor では DI が使えるので、まずは SignInManager を使ってサインインしてみることにしました。
ApplicationUserService.cs
...
public async Task<bool> SignInAsync(string email, string password)
{
var target = await applicationUsers.GetByEmailAsync(email);
if (target == null)
{
return false;
}
var result = await signInManager.PasswordSignInAsync(target, password, false, false);
return result.Succeeded;
}
...
SignIn.razor
@page "/Pages/SignIn" <div id="background"> <div id="sign_in_frame"> <h1>Sign In</h1> <div class="sign_in_input_container"> <input type="text" @bind="Email" class="sign_in_input @AdditionalClassName"> </div> <div class="sign_in_input_container"> <input type="password" @bind="Password" class="sign_in_input @AdditionalClassName"> </div> <div id="sign_in_controller_container"> <button @onclick="StartSigningIn">Sign In</button> </div> </div> </div>
SignIn.razor.cs
using System; using System.Threading.Tasks; using Microsoft.AspNetCore.Components; using Microsoft.JSInterop; using ApprovementWorkflowSample.Applications; namespace ApprovementWorkflowSample.Views { public partial class SignIn { [Inject] public IJSRuntime? JSRuntime { get; init; } [Inject] public NavigationManager? Navigation { get; init; } [Inject] public IApplicationUserService? ApplicationUsers{get; init; } [Parameter] public string Email { get; set; } = ""; [Parameter] public string Password { get; set; } = ""; [Parameter] public string AdditionalClassName { get; set; } = ""; public async Task StartSigningIn() { if(string.IsNullOrEmpty(Email) || string.IsNullOrEmpty(Password)) { await HandleSigningInFailedAsync("Email と Password は入力必須です"); return; } var result = await ApplicationUsers!.SignInAsync(Email, Password); if(result) { // サインインに成功したら次のページへ Navigation!.NavigateTo("/Pages/Edit"); return; } AdditionalClassName = "login_failed"; await JSRuntime!.InvokeAsync<object>("Page.showAlert","Email か Password が違います"); } private async Task HandleSigningInFailedAsync(string errorMessage) { AdditionalClassName = "login_failed"; await JSRuntime!.InvokeAsync<object>("Page.showAlert", errorMessage); } } }
実行してみると、「SignInAsync」を呼ぶところで例外が発生しました。
Unhandled exception rendering component: Headers are read-only, response has already started. System.InvalidOperationException: Headers are read-only, response has already started. at Microsoft.AspNetCore.Server.Kestrel.Core.Internal.Http.HttpHeaders.ThrowHeadersReadOnlyException() ...
この方法はダメなようです。
Controller からサインイン(失敗)
JavaScript などからサインインするのと同じように、 Controller を通してサインインしてみることにしました。
UserController.cs
...
[HttpPost]
[Route("Users/SignIn")]
public async ValueTask<bool> SignIn([FromBody]SignInValue value)
{
if(string.IsNullOrEmpty(value.Email) ||
string.IsNullOrEmpty(value.Password))
{
return false;
}
return await users.SignInAsync(value.Email, value.Password);
}
...
SignInValue.cs
namespace ApprovementWorkflowSample.Applications.Dto { public record SignInValue(string Email, string Password); }
SignIn.razor.cs
using System.IO; using System.Text; using System.Net.Http; using System.Threading.Tasks; using ApprovementWorkflowSample.Applications.Dto; using Microsoft.AspNetCore.Components; using Microsoft.JSInterop; using Microsoft.Extensions.Configuration; using ApprovementWorkflowSample.Applications; using Newtonsoft.Json; namespace ApprovementWorkflowSample.Views { public partial class SignIn { [Inject] public IJSRuntime? JSRuntime { get; init; } [Inject] public IHttpClientFactory? HttpClients { get; init; } [Inject] public IConfiguration? Configuration { get; init; } [Inject] public NavigationManager? Navigation { get; init; } ... public async Task StartSigningIn() { ... var httpClient = HttpClients.CreateClient(); var signInValue = new SignInValue(Email, Password); var context = new StringContent(JsonConvert.SerializeObject(signInValue), Encoding.UTF8, "application/json"); var response = await httpClient.PostAsync(Path.Combine(Configuration!["BaseUrl"], "Users/SignIn"), context); if(response.IsSuccessStatusCode == false) { await HandleSigningInFailedAsync("アクセス失敗"); return; } string resultText = await response.Content.ReadAsStringAsync(); bool.TryParse(resultText, out var result); if(result) { Navigation!.NavigateTo("/Pages/Edit"); return; } AdditionalClassName = "login_failed"; await HandleSigningInFailedAsync("Email か Password が違います"); } ...
例外は発生せず、戻り値としては「true」が得られるのですが、認証済みとは扱われませんでした。
EditWorkflow.razor
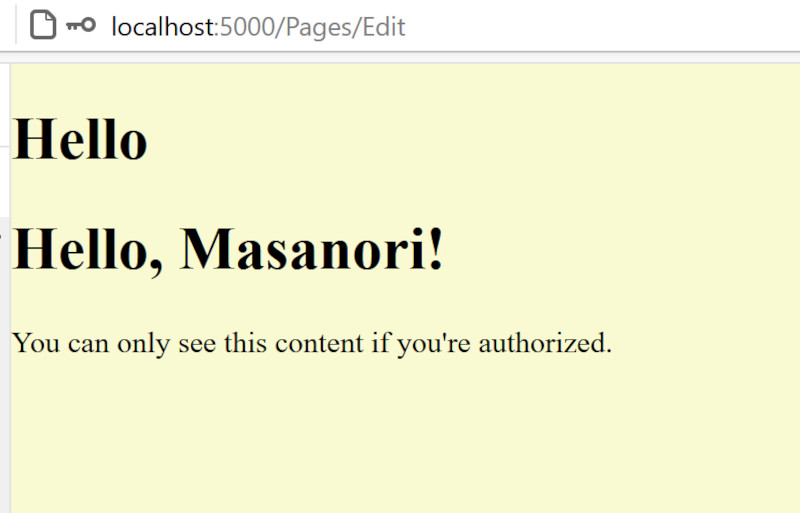
@page "/Pages/Edit" @attribute [Authorize] <CascadingAuthenticationState> <AuthorizeView> <Authorized> <h1>Hello, @context.User.Identity!.Name!</h1> <p>You can only see this content if you're authorized.</p> </Authorized> <NotAuthorized> <h1>Authentication Failure!</h1> <p>You're not signed in.</p> </NotAuthorized> </AuthorizeView> </CascadingAuthenticationState>
認証処理が完了した後も、「NotAuthorized」の要素が表示されます。
どうもこれは、 Controller を通して認証するのは、 HTTP を使うのに対し、 Blazor Server アプリケーションとサーバーとの接続には SignalR を使っていることが原因のようです。
ClaimsPrincipal 、ClaimsIdentity 、AuthenticationState を使う(OK)
先ほどの記事を参考に、「IHostEnvironmentAuthenticationStateProvider」の追加と「SignIn.razor.cs」の変更を試してみることにします。
Startup.cs
...
public void ConfigureServices(IServiceCollection services)
{
...
services.AddScoped<IHostEnvironmentAuthenticationStateProvider>(sp =>
(ServerAuthenticationStateProvider) sp.GetRequiredService<AuthenticationStateProvider>()
);
...
}
...
SignIn.razor.cs
using System.Threading.Tasks; using Microsoft.AspNetCore.Components; using Microsoft.JSInterop; using ApprovementWorkflowSample.Applications; using Microsoft.AspNetCore.Identity; using System.Security.Claims; using Microsoft.AspNetCore.Components.Authorization; using Microsoft.AspNetCore.Authentication.Cookies; namespace ApprovementWorkflowSample.Views { public partial class SignIn { [Inject] public IJSRuntime? JSRuntime { get; init; } [Inject] public NavigationManager? Navigation { get; init; } [Inject] public IApplicationUserService? ApplicationUsers{get; init; } [Inject] public SignInManager<ApplicationUser>? SignInManager { get; init; } [Inject] public IHostEnvironmentAuthenticationStateProvider? HostAuthentication { get; init; } [Inject] public AuthenticationStateProvider? AuthenticationStateProvider{get; init; } ... public async Task StartSigningIn() { ... ApplicationUser? user = await ApplicationUsers!.GetUserByEmailAsync(Email); if(user == null) { await HandleSigningInFailedAsync("Email か Password が違います"); return; } SignInResult loginResult = await SignInManager!.CheckPasswordSignInAsync(user, Password, false); if(loginResult.Succeeded == false) { await HandleSigningInFailedAsync("Email か Password が違います"); return; } if(loginResult.Succeeded) { ClaimsPrincipal principal = await SignInManager.CreateUserPrincipalAsync(user); ClaimsIdentity identity = new ClaimsIdentity(principal.Claims, CookieAuthenticationDefaults.AuthenticationScheme); SignInManager.Context.User = principal; HostAuthentication!.SetAuthenticationState( Task.FromResult(new AuthenticationState(principal))); AuthenticationState authState = await AuthenticationStateProvider!.GetAuthenticationStateAsync(); Navigation!.NavigateTo("/Pages/Edit"); } } ...
ようやくサインインと、サインイン完了後に「認証済み」として扱われるようになりました。
未認証ユーザーの自動リダイレクト
ASP.NET Core では、未認証ユーザーが認証が必要なルートにアクセスした際、自動でログインページに遷移させる仕組みがあります。
では Blazor は?
デフォルトで設定してくれる仕組みは見つけられなかったため、下記の記事を参考にリダイレクトさせることにしました。
App.razor
@using Shared <CascadingAuthenticationState> <Router AppAssembly="@typeof(Program).Assembly" PreferExactMatches="@true"> <Found Context="routeData"> <AuthorizeRouteView RouteData="@routeData" DefaultLayout="@typeof(MainLayout)"> <NotAuthorized> <RedirectToSignIn></RedirectToSignIn> </NotAuthorized> </AuthorizeRouteView> </Found> <NotFound> <LayoutView Layout="@typeof(MainLayout)"> <p>Sorry, there's nothing at this address.</p> </LayoutView> </NotFound> </Router> </CascadingAuthenticationState>
RedirectToSignIn.razor.cs
using System.Threading.Tasks; using Microsoft.AspNetCore.Components; using Microsoft.AspNetCore.Components.Authorization; namespace ApprovementWorkflowSample.Views { public partial class RedirectToSignIn { [CascadingParameter] private Task<AuthenticationState>? AuthenticationStateTask { get; init; } [Inject] public NavigationManager? Navigation { get; init; } protected override async Task OnInitializedAsync() { var authenticationState = await AuthenticationStateTask!; if (authenticationState?.User?.Identity is null || !authenticationState.User.Identity.IsAuthenticated) { var returnUrl = Navigation!.ToBaseRelativePath(Navigation.Uri); if (string.IsNullOrWhiteSpace(returnUrl)) { Navigation.NavigateTo("Pages/SignIn", true); } else { Navigation.NavigateTo($"Pages/SignIn?returnUrl={returnUrl}", true); } } } } }
- 今回端折ってますが、 SignIn.razor で「returnUrl」を受け取る仕組みは必要です